

Studien belegen: Datengetriebene Unternehmen sind erfolgreicher als andere. Aber welche Rolle spielen Daten und Schnittstellen für das Geschäft der Zukunft? Und wie baut man moderne Datennetzwerke aus verlinkten Daten auf? In einer Artikelserie befassen wir uns mit dem Thema Linked Data. Im weiteren Verlauf unserer Reihe bewerten wir BiPRO und die Norm 430 vor diesem Hintergrund. Im ersten Artikel geht es heute darum, wie sich das Internet fast unbemerkt zum Web of Data entwickelt (hat) und worum es bei Linked Data (LD) eigentlich geht.
Wie entwickelt sich das Internet weiter?
Das heutige Internet besteht hauptsächlich aus verlinkten Webseiten. Es wurde für Menschen gemacht. Im künftigen Web geht es um verknüpfte Daten. Es ist für Maschinen gemacht. So wie unstrukturierte und für Menschen lesbare Informationen im klassischen Web über Hyperlinks miteinander verknüpft sind, werden zunehmend auch strukturierte Datensätze über Hyperlinks miteinander verknüpft. Wir haben also in Zukunft ein Netz aus verknüpften Daten. In diesem Datennetz werden Daten mit Bedeutung angereichert, damit Maschinen sie besser verstehen können.
Einerseits geht es also darum, nicht länger nur unstrukturierte Informationen in natürlicher Sprache zu schreiben und per HTML für den Menschen im Browser verfügbar zu machen. Vielmehr geht es künftig darum, Inhalte in Form von strukturierten Daten zu beschreiben, damit Maschinen sie verwenden können. Diese strukturierten Datensätze können einfach in eine Website (für Menschen unsichtbar) eingebettet oder über eine eigenständige Internet-Adresse abgerufen werden. In diesem Fall sprechen wir nicht mehr von einer Website, sondern von einem so genannten Application Programming Interface, kurz API oder auch Programmierschnittstelle genannt.
Aber meistens folgen diese eingebetteten oder per URL abrufbaren Daten der individuellen Syntax und Grammatik ihrer Anbieter. Mit anderen Worten: Jeder Datenprovider spricht seine eigene Sprache. Dies ist ein Problem, das wir in der Geschichte meist über standardisierte Datenmodelle lösen wollten. Wir wollten zum Beispiel die Namen von Feldern festlegen. Dann musste jeder seine eigenen Daten und Schnittstellen standardkonform transformieren. Bei Änderungen muss jeder die Schnittstellenimplementierung ändern. Allerdings hat das in der Vergangenheit nicht gut funktioniert, weil es viel Arbeit für alle war und die Qualität des Datenaustauschs durch Fehlinterpretationen leidet. Hinzu kommt, dass ein Standard nie 100 Prozent aller individuellen Anwendungsfälle abbilden kann. Stattdessen wäre es also besser, die Dinge so zu lassen, wie sie sind, und Heterogenität einfach zu akzeptieren, anstatt die Dinge gleich machen zu wollen, richtig? Geht es nicht vielmehr darum, die Individualität zu handhaben? An dieser Stelle kommt Semantik ins Spiel.
Was ist Linked Data?
Um tiefere Einblicke zu bekommen, lassen Sie uns auf die gezeigte Grafik eingehen: Das klassische Internet besteht aus Webseiten, die über Hyperlinks miteinander verbunden sind. Webseiten sind HTML-Dokumente, die Inhalte für Menschen aufbereiten. Deshalb wird das World Wide Web auch Web of Documents genannt. Tatsächlich sprechen wir von einem Graphen, weil es weder Anfang noch Ende und keine Hierarchie gibt. Jede Webseite stellt einen Knoten dieses Graphens dar, der über Kanten mit anderen Knoten verbunden ist. Beim Web of Data handelt es sich also um einen Graphen, bei dem die Knoten nicht Webseiten, sondern Datensätze sind. Ein Knoten ist normalerweise über Kanten mit einem oder mehreren anderen Knoten verbunden.
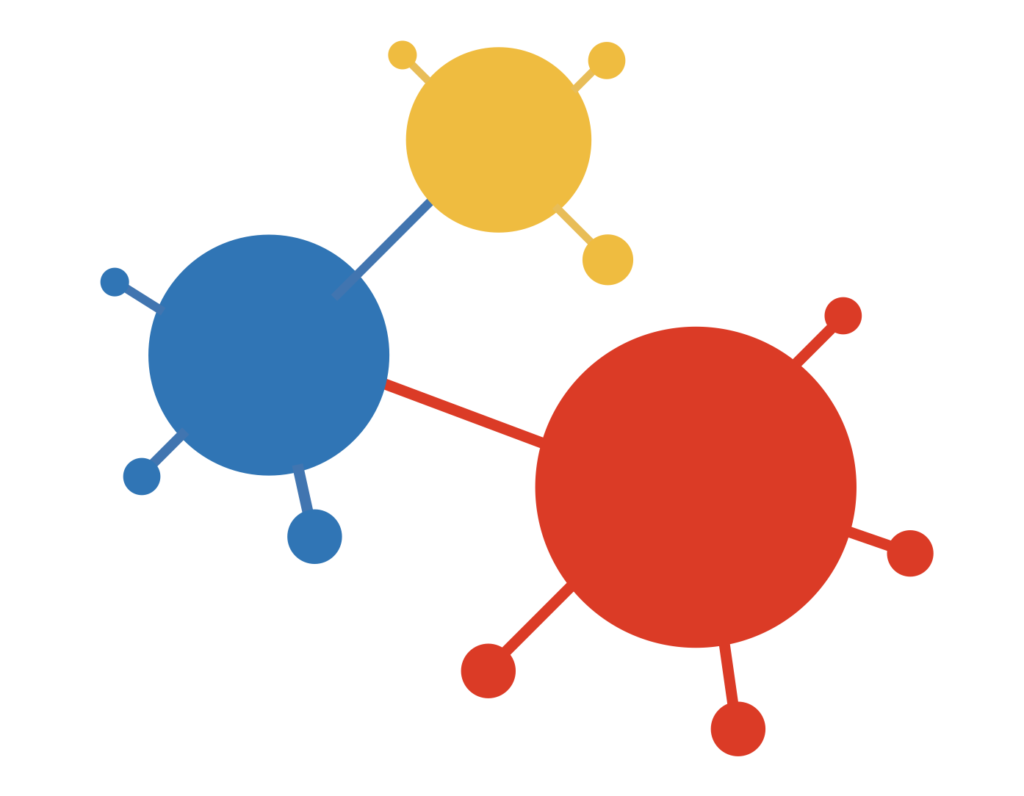
Lassen Sie den roten Kreis einen Knoten sein, auf den per URL zugegriffen werden kann, damit Sie ihn über HTTP laden können. Nichts anderes macht Ihr Browser, wenn Sie eine Internetadresse eingeben. Der Knoten selbst ist aber keine HTML-Webseite, sondern ein so genanntes JSON-Objekt, das Attribute bzw. Eigenschaften hat. Dieses Objekt könnte z.B. eine Person repräsentieren und die Attribute des Objektes könnten der Vorname, der Nachname, das Geschlecht und das Geburtsdatum sein. Dies sind die kleinen roten Punkte, die aus dem Knoten herausragen, den Sie in der Grafik sehen können. Der Knoten selbst wiederum ist über die rote Kante mit einem blauen Knoten verbunden. Dies ist ein Link, ähnlich einem Link auf einer Webseite. Dieser Link könnte bedeuten, dass die Person eine andere Person kennt. Der blaue Knoten könnte also eine andere Person sein, die ebenfalls Eigenschaften hat.
Wenn der rote Kreis eine Person in Form von Daten ist und auch der blaue Kreis, warum haben sie dann unterschiedliche Farben? Gibt es einen Unterschied zwischen der roten und der blauen Person? Die Antwort ist: ja. Beide Knoten sind über unterschiedliche URLs aufrufbar und kommen von unterschiedlichen Anbietern. Außerdem ist der Datensatz hinter jeder URL anders strukturiert, weil sich zum Beispiel die Namen der Attribute unterscheiden, weil jeder Anbieter seine eigene Datensatzstruktur mit Feldnamen und Datentypen verwendet. Es sind also nicht dieselben Personen. Das ist ein Problem. Eine Maschine kann die Links in den Daten zwar finden und ihnen auch folgen, so wie ein Mensch die Links auf Webseiten anklicken kann. Aber was hilft das, wenn ich so von einer deutschsprachigen zu einer japanischen Webseite gelange, deren Sprache ich nicht verstehe. Genau dieses Problem hat auch eine Maschine, wenn sie Datensätze verarbeiten soll, die sie nicht kennt.
Es dreht sich also alles irgendwie um die Verlinkung von Daten aus unterschiedlichen Datenquellen und deren Bedeutung. Lesen Sie mehr dazu in unserem zweiten Artikel zum Thema Linked Data und die Bedeutung.



1 Kommentar
[…] ersten Beitrag unserer Artikelserie haben Sie erfahren, worum es bei Linked Data geht. Das so genannte Web of Data folgt den […]